
|
|
ODDS RATIO CHI-SQUARE TESTName:
= (N11N22)/ (N12N21) where
N21 = number of failures in sample 1 N12 = number of successes in sample 2 N22 = number of failures in sample 2 The first definition shows the meaning of the odds ratio clearly, although it is more commonly given in the literature with the second definition. The log odds ratio is the logarithm of the odds ratio:
= LOG{(N11N22)/ (N12N21)} Alternatively, the log odds ratio can be given in terms of the proportions
= LOG{(p11p22)/ (p12p21)} where
= proportion of successes in sample 1 p21 = N21/ (N11 + N21) = proportion of failures in sample 1 p12 = N12/ (N12 + N22) = proportion of successes in sample 2 p22 = N22/ (N12 + N22) = proportion of failures in sample 2 Success and failure can denote any binary response. Dataplot expects "success" to be coded as "1" and "failure" to be coded as "0". The bias corrected version of the statistic is:
In addition to reducing bias, this statistic also has the advantage that the odds ratio is still defined even when N12 or N21 is zero (the uncorrected statistic will be undefined for these cases). Note that N11, N21, N12, and N22 defines a 2x2 contingency table. These types of contingency tables are also referred to as fourfold tables. The odds ratio chi-square test is applied in the situation where we have a series of fourfold tables. That is, the two variables for the fourfold tables are the same, but data is collected from different populations or groups with regards to these variables. Fleiss, Levin, and Paik (p. 234) list the following questions that are typically asked about these type of data: Suppose we have g fourfold tables. Then
This test is based on decomposing the total chi-square in the following way:
The \( \chi_{\mbox{homogeneity}}^{2} \) assesses the degree of homogeneity (i.e., equality) among the g measures of association. The \( \chi_{\mbox{association}}^{2} \) assesses the significance of the average degree of association. The overall measure of association (across all groups) is the weighted average of the g individual measures:
Under the hypothesis of zero overall association, \( \bar{Y} \) has an average value of zero and a standard error of
From this
follows an approximately a standard normal distribution under the null hypothesis and
follows an approximately chi-square distribution with one degree of freedom. In addition,
follows an approximately chi-square distribution with g - 1 degrees of freedom. Note that \( \chi_{\mbox{association}}^{2} \) and \( \chi_{\mbox{homogeneity}}^{2} \) are uncorrelated. Based on the above formulas, we can answer the above questions as follows.
The above discussion is based on a generic statistic for the measure of association. For the odds ratio chi-square test, the specific measure of association is the bias corrected log odds ratio (given above). Note that the standard error of the bias corrected log odds ratio is:
The ODDS RATIO CHI-SQUARE TEST generates the following output:
<SUBSET/EXCEPT/FOR qualification> where <y1> is the first response variable; <y2> is the second response variable; and where the <SUBSET/EXCEPT/FOR qualification> is optional. This syntax is used for the case where <y1> and <y2> denote a series of 2x2 tables (i.e., rows 1 and 2 are group 1, rows 3 and 4 are group 2, and so on).
<SUBSET/EXCEPT/FOR qualification> where <y1> is the first response variable; <y2> is the second response variable; <groupid> is a group id variable; and where the <SUBSET/EXCEPT/FOR qualification> is optional. This syntax is used for the case where you have raw data (i.e., the data has not yet been cross tabulated into a two-way table). In this case, the two response variables have an equal number of cases for each group.
<SUBSET/EXCEPT/FOR qualification> where <y1> is the first response variable; <groupid1> is a group id variable corresponding to <y1>; <y2> is the second response variable; <groupid2> is a group id variable corresponding to <y2>; and where the <SUBSET/EXCEPT/FOR qualification> is optional. This syntax is used for the case where you have raw data (i.e., the data has not yet been cross tabulated into a two-way table). In this case, the two response variables may have an unequal number of cases for each group, so <y1> and <y2> require different group id variables.
ODDS RATIO CHI-SQUARE TEST Y1 Y2 X ODDS RATIO CHI-SQUARE TEST Y1 X1 Y2 X2
To read this information into Dataplot, enter
READ DPST1F.DAT SIGLEV LOGLOWCL LOGUPPCL ODDLOWCL ODDUPPCL Dataplot saves the following internal parameters:
let n1 = 105
let n2 = 192
let n3 = 145
let n = n1 + n2 + n3
let x = 3 for i = 1 1 n
let istop = n1 + n2
let x = 2 for i = 1 1 istop
let x = 1 for i = 1 1 n1
.
set statistic missing value -99
.
. Group 1 values
.
let y1 = 0 for i = 1 1 n
let y2 = 0 for i = 1 1 n
let y1 = 1 for i = 1 1 81
let y2 = 1 for i = 1 1 34
.
. Group 2 values (have unequal samples here, so fill
. with missing values
.
let istrt = n1 + 1
let istop1 = istrt + 118 - 1
let istop2 = istrt + 69 - 1
let y1 = 1 for i = istrt 1 istop1
let y2 = 1 for i = istrt 1 istop2
let istrt2 = n1 + 174 + 1
let istop2 = n1 + n2
let y2 = -99 for i = istrt2 1 istop2
.
. Group 3 values
.
let istrt = n1 + n2 + 1
let istop1 = istrt + 82 - 1
let istop2 = istrt + 52 - 1
let y1 = 1 for i = istrt 1 istop1
let y2 = 1 for i = istrt 1 istop2
.
odds ratio chi-square test y1 y2 x
The following output is generated.
SUMMARY OF LOG(ODDS RATIO)
| LOG OF STANDARD
| ODDS RATIO ODDS RATIO ERROR 1/SE(L(i))**2 w(i)*
GROUP | O(i) L(i) SE(L(i)) w(i) L(i)**2
===============================================================================
1. | 6.894114 1.930668 0.3099319 10.41040 38.80455
2. | 2.414514 0.8814980 0.2138429 21.86806 16.99233
3. | 2.313836 0.8389067 0.2400251 17.35748 12.21558
===============================================================================
TOTAL | 49.63593 68.01245
CHI-SQUARE ANALYSIS OF LOG(ODDS RATIO)
NUMBER OF GROUPS = 3
ESTIMATE OF COMBINED LOG(ODDS RATIO) = 1.086652
STANDARD ERROR OF COMBINED LOG(ODDS RATIO) = 0.1419390
CHI-SQUARE TEST STATISTIC (TOTAL) = 68.01245
DEGRESS OF FREEDOM = 3
CDF OF TEST STATISTIC = 1.000000
CHI-SQUARE TEST STATISTIC (ASSOCIATION) = 58.61073
DEGRESS OF FREEDOM = 1
CDF OF TEST STATISTIC = 1.000000
CHI-SQUARE TEST STATISTIC (HOMOGENEITY) = 9.401718
DEGRESS OF FREEDOM = 2
CDF OF TEST STATISTIC = 0.9978321
CHI-SQUARE TEST FOR CONSISTENCY OF ASSOCIATION (HOMOGENEITY)
NULL HYPOTHESIS NULL
NULL CONFIDENCE CRITICAL ACCEPTANCE HYPOTHESIS
HYPOTHESIS LEVEL VALUE INTERVAL CONCLUSION
===================================================================
CONSISTENT 50.0% 1.39 (0,0.500) REJECT
CONSISTENT 80.0% 3.22 (0,0.800) REJECT
CONSISTENT 90.0% 4.61 (0,0.900) REJECT
CONSISTENT 95.0% 5.99 (0,0.950) REJECT
CONSISTENT 97.5% 7.38 (0,0.975) REJECT
CONSISTENT 99.0% 9.21 (0,0.990) REJECT
CHI-SQUARE TEST FOR OVERALL DEGREE OF ASSOCIATION
NULL HYPOTHESIS NULL
NULL CONFIDENCE CRITICAL ACCEPTANCE HYPOTHESIS
HYPOTHESIS LEVEL VALUE INTERVAL CONCLUSION
===================================================================
NO ASSOCIATION 50.0% 0.45 (0,0.500) REJECT
NO ASSOCIATION 80.0% 1.64 (0,0.800) REJECT
NO ASSOCIATION 90.0% 2.71 (0,0.900) REJECT
NO ASSOCIATION 95.0% 3.84 (0,0.950) REJECT
NO ASSOCIATION 97.5% 5.02 (0,0.975) REJECT
NO ASSOCIATION 99.0% 6.63 (0,0.990) REJECT
LARGE SAMPLE CONFIDENCE INTERVAL FOR LOG(ODDS RATIO)
LOG(ODDS RATIO) ODDS RATIO
( 1.086652 ) ( 2.964333 )
CONFIDENCE LOWER UPPER LOWER UPPER
VALUE (%) LIMIT LIMIT LIMIT LIMIT
-----------------------------------------------------------------------
50.000 0.990915 1.18239 2.69370 3.26216
80.000 0.904750 1.26855 2.47131 3.55571
90.000 0.853183 1.32012 2.34711 3.74387
95.000 0.808457 1.36485 2.24444 3.91513
97.500 0.768509 1.40479 2.15655 4.07469
99.000 0.721041 1.45226 2.05657 4.27277
Date created: 10/10/2008 |
Last updated: 12/11/2023 Please email comments on this WWW page to [email protected]. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
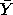 and a large sample confidence interval is
and a large sample confidence interval is