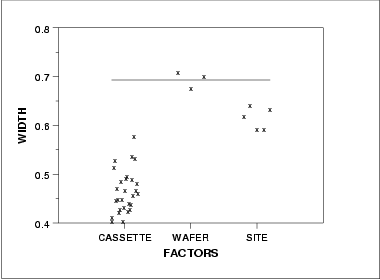
6.6. Case Studies in Process Monitoring
6.6.1. Lithography Process
6.6.1.2. |
Graphical Representation of the Data |
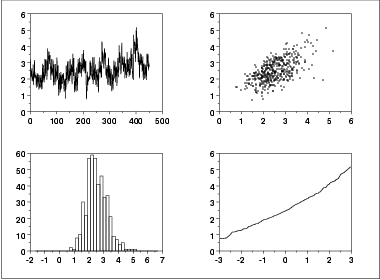
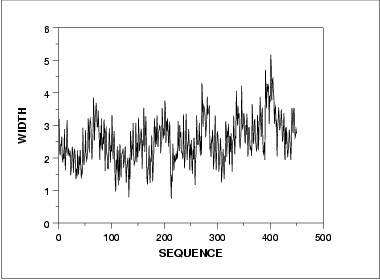
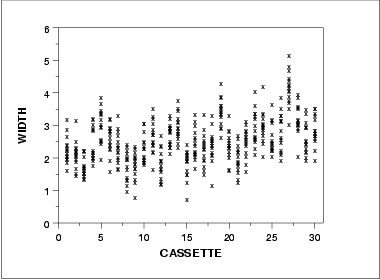
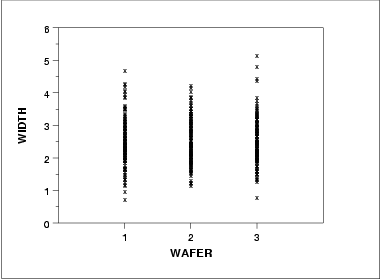
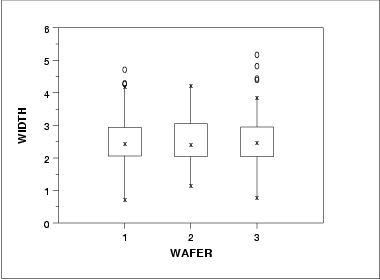
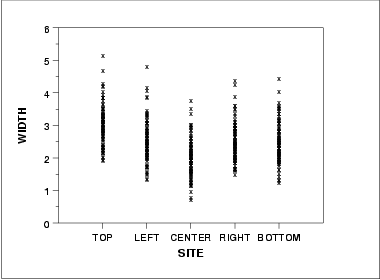
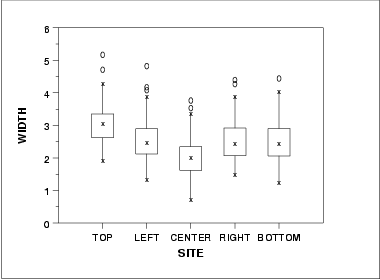
- The run sequence plot (upper left) indicates that the location and scale are not constant over time. This indicates that the three factors do in fact have an effect of some kind.
- The lag plot (upper right) indicates that there is some mild autocorrelation in the data. This is not unexpected as the data are grouped in a logical order of the three factors (i.e., not randomly) and the run sequence plot indicates that there are factor effects.
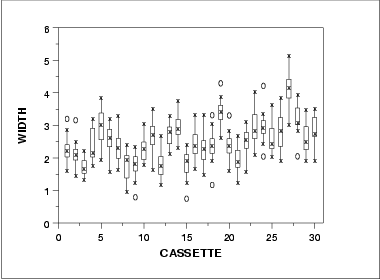
- The histogram (lower left) shows that most of the data fall between 1 and 5, with the center of the data at about 2.2.
- Due to the non-constant location and scale and autocorrelation in the data, distributional inferences from the normal probability plot (lower right) are not meaningful.