|
TIPSTER Text Program A multi-agency, multi-contractor program |
|
TABLE OF CONTENTS Introduction TIPSTER Overview TIPSTER Technology Overview TIPSTER Related Research Phase III Overview TIPSTER Calendar Reinvention Laboratory Project What's New Conceptual Papers Generic Information Retrieval Generic Text Extraction Summarization Concepts 12 Month Workshop Notes Conferences Text Retrieval Conference Multilingual Entity Task Summarization Evaluation More Information Other Related Projects Document Down Loading Request for Change (RFC) Glossary of Terms TIPSTER Source Information Return to Retrieval Group home page Return to IAD home page Last updated: Date created: Monday, 31-Jul-00 |
Generic Information Retrieval SystemAn information retrieval application is a collection of components which selects and returns to the user desired documents from a large set of documents (the corpus) in accordance with criteria (Detection Need) specified by the user. Information Retrieval (or Document Detection, as it is also called) performs two functions:
A Detection Need is a set of criteria specified by the user which describes the kind of information desired. Detection Needs are frequently called queries when they occur in the Document Search task and are referred to as profiles in the Routing Task. Document Needs can be expressed in terms of keywords, keywords with Boolean operators, statements in free text, or example documents, depending upon the system. Until recently most systems have required the user to produce keyword or Boolean keyword queries. With advances in the field, users can define their Detection Needs in terms of free-text and example documents. Document are generally returned to the user in the form of lists of document citations. These lists may be unordered. However, many systems rank order the documents, generally placing the documents most likely to be relevant at the top of the list, with less relevant document placed lower on the list. The accuracy and utility of such systems is often measured by their ability to place most documents of interest to the user in the top part of the document list. The main difference between search and routing is that the search process matches a single Detection Need against the stored corpus to return a sub-set of documents whereas routing matches a single document as it enters the system against a group of Profiles to determine which users are interested in the document. Profiles, therefore tend to be standing and long-term expressions of user needs, whereas search queries are typically ad hoc in nature. A generic detection architecture can be used for both the search and routing. Each of these tasks is discussed separately below, but the similarities should be apparent both in the figures and in the descriptions. SearchSearch is the retrieval of desired documents from an existing corpus. Retrospective search is frequently interactive. As the user produces increasingly better search queries based on the results of initial searches and the user's developing concept of his/her information need. There are several methods that can be used to perform the search function; however, indexing the corpus by keyword, stem and/or phrase is central to most methods. Some methods apply statistical and/or learning techniques to better understand the content of the corpus and to determine appropriate keywords. Some methods also analyze free text Detection Needs to allow comparison with the indexed corpus or a single document. Search can be understood in terms of a set of modules shown in Figure 1. Any particular document detection system uses own set of modules which may vary slightly from the ones described below. The modules are:
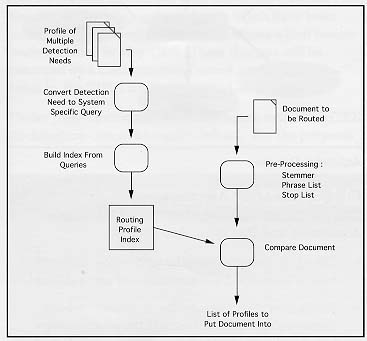
Figure 1. Document Detection : Search 1. Document CorpusA corpus is comprised of the source documents from which the user will select the document sub-set. The content of the corpus may have significant the performance in some applications. Its documents may be part of a vary narrowly defined subject domain, or may pertain to a broad range of concepts covering several subject domains. Thus, different detection systems may have varying performance, depending upon the content of the corpus and the Detection Need. TIPSTER detection applications have been developed and tested against a corpus of several gigabytes of text covering multiple subject domains. 2. Pre-Processing of Document CorpusPre-processing of the corpus is an area of continuing research and is a key discriminator in Document Detection methods. Most systems use some method of stemming. Stemming is the reduction of a word to its root. For example, "Contrary, Contradiction, Contraband" all have 'contra' as a stem which permits a certain amount of generalization over the meaning of the sentences or document. Most systems also use a list of Stop words. A Stop word is a word which is usually ignored, e.g., 'a', 'an', 'the'. Stop words lack significance to the determination of the subject of a document at the rather general level at which document detection works. Research is progressing at identifying phrases and multi-term items such as dates and personal names so that these can be indexed as single terms. 3. Building Index from StemsThis function is frequently very system specific because it is a key place in the detection system for optimizing run-time performance. Document Detection systems in general are concerned with speed due to the very large number of the documents to be searched. It may take a very long time to build the index for a large corpus. New indexes may only be built weekly or even less often. Some provision is always made for incrementally indexing documents that have been added to the corpus since the last full indexing. 4. Document IndexA document index is essentially a list of terms, stems, phrases, etc. (depending upon the search algorithm) with each term having an associated list of document identifiers which point to documents and stem locations that contain the particular item. Further information resulting from analyses of the frequency of terms in the document and corpus and of the co-occurrence of terms within the corpus may also be stored in the index to aid in the ranking of documents in the returned document set. Frequently the index may be as large as the original document corpus and various design and compression techniques are usually used to condense it. 5. Detection NeedA Detection Need expresses the user's criteria for a relevant document. A Detection Need may take a number of forms described at the beginning of this paper. In the TIPSTER architecture the design of the Detection Need has been made generic to allow use of any or all of these forms: This is a sample Detection Need Studies about economic indicators as they would apply to or be used in analyzing financial markets in European countries 6. Convert Detection Need to System Specific QueryWhen being processed the Detection Need is transformed in two stages: it is first transformed into a detection query, and then into a retrieval query. Some information in the Detection Need, such as keywords, may not require transformation. Detection Needs are independent of the specific retrieval engine employed, while detection queries and retrieval queries are specific to a particular retrieval engine. By de-coupling the Detection Need and the system specific query, detection systems can more easily be ported to different domains and employ different indexing algorithms. This allows a more consistent interface with the user. The detection query is specific to the retrieval engine but independent of the corpus over which retrieval is to be performed. The retrieval query is specific to the retrieval engine, to the operation, and to the corpus. The retrieval query may incorporate term weights based on the inverse document frequencies in a collection. The interpretation, translation and processing of a Detection Need is also performance sensitive part of the Detection application. Again, because of the large number of documents against which it will be compared. Research is progressing on the use of phrase lists and term expansion when determining system specific queries. Certain words or phrases are replaced with more informative words which are determined from the document corpus itself. Abbreviations are frequently expanded to their full meaning. 7. Compare Query with IndexIn attempting to select a desired document the query is compared item by item with the corpus index, recognizing any imbedded logic, such as include - do not include. It is not necessary to examine each document in the corpus since it's important constituent items were placed in the index prior to the query comparison. The use of an index significant improves the time, typically a few seconds, required to identify a document. 8. Resultant Rank Ordered List of DocumentsThe list of relevant documents that results from the comparison process is ranked ordered from the most relevant to the query to the least relevant. This is accomplished through the use of various weighting algorithms which are dependent upon the particular detection system. For example, a document, which met every criterion in the Detection Need, would be at the top of the list and a document which met 90% of the criteria may be further down the list. Document Detection systems typically rank order all the documents in the corpus but only return the top 'N' documents depending upon the desired cut-off specified. RoutingThe goal of routing is to decide which user would be interested in each document in a corpus. Usually routing is applied to new incoming documents as opposed to archived documents. Any given document may be of interest to several users and each would be notified of the existence of the document. A user's interest is specified in an individual Profile. The Profile may be composed of multiple Detection Needs. Routing employs a set of modules as shown in Figure 2. Any particular Detection system will use its own set of modules which may very slightly with the ones described below. The modules used by this generic routing system are:
Figure 2. Document Detection : Routing 1. Profile of Multiple Detection NeedsA Profile is a group individual Detection Needs that describes a user's areas of interest. All Profiles will be compared to each incoming document (via the Profile index) to determine if any matches exist. If a document matches a Profile the user is notified about the existence of a relevant document. 2. Convert Detection Need to System Specific QueryWhen being processed the Detection Need is transformed in two stages: it is first transformed into a detection query, and then into a routing query. Some information in the Detection Need, such as keywords, may not require transformation. The Detection Need used in routing is the same Detection Need used in searching and it is converted to a specific query in the same way as in search. 3. Building Index from QueriesBuilding a routing profile index from the Profiles is similar to building the corpus index for searching, described above. The only differences are that the quantity of source data (Profiles) is usually much less than a document corpus. Additionally, Profiles may have more specific, structured data in the form of SGML tagged fields. 4. Routing Profile IndexThe index will be system specific and will make use of all the pre-processing techniques employed by a particular detection system. 5. Document to be RoutedA stream of incoming documents is handled one at a time to determine where each should be directed. Routing implementations may handle multiple document streams and multiple Profiles. 6. Pre-Processing of DocumentA document is pre-processed in the same manner that a query would be set-up in a search, described above. In the case of routing the document and query roles are reversed compared with the search process. 7. Compare Document with IndexA comparison of a document against the query index identifies which queries and in turn, which Profiles, are relevant to the document. Essentially, the document in routing is analogous to the query in searching. The problem can be stated as, given this document, which of the indexed profiles match it? 8. Resultant List of ProfilesThe list of Profiles that was created by the matching process identifies which users should receive the document since each Profile is owned by a specific user. A Final WordDocument Detection is a mature technology with reliable and consistent implementations. However, advances continue to be made, particularly in the areas of expanding Detection Needs and in the conversion of Detection Needs to system specific queries.
|