
5.5. Advanced topics
5.5.9. An EDA approach to experimental design
5.5.9.9. |
Cumulative residual standard deviation plot |
-
What is a good model for the data?
- Factors: determining the most important factors that affect the response, and
- Settings: determining the best settings for these factors.
- Model: determining a model (that is, a prediction equation) that functionally relates the observed response Y with the various main effects and interactions.
In the continuous-factor case, the analyst could use such a function for the following purposes.
- Reproduction/Smoothing: predict the response at the observed design points.
- Interpolation: predict what the response would be at (unobserved) regions between the design points.
- Extrapolation: predict what the response would be at (unobserved) regions beyond the design points.
In modeling, we seek a function f in the k factors X1, X2, ..., Xk such that the predicted values
-
\( \hat{Y} = f(X_{1}, X_{2}, \ldots , X_{k}) \)
- Determine a good functional form f;
- Determine good estimates for the coefficients in that function f.
- determine some function f(X1,X2); and
- estimate the parameters in f
For a given model, a statistic that summarizes the quality of the fit via the typical size of the n residuals is the residual standard deviation:
-
\( s_{res} = \sqrt{\frac{\sum_{i=1}^{n}{r_{i}^{2}}}{n-p}} \)
If we have a good-fitting model, sres will be small. If we have a poor-fitting model, sres will be large.
For a given data set, each proposed model has its own quality of fit, and hence its own residual standard deviation. Clearly, the residual standard deviation is more of a model-descriptor than a data-descriptor. Whereas "nature" creates the data, the analyst creates the models. Theoretically, for the same data set, it is possible for the analyst to propose an indefinitely large number of models.
In practice, however, an analyst usually forwards only a small, finite number of plausible models for consideration. Each model will have its own residual standard deviation. The cumulative residual standard deviation plot is simply a graphical representation of this collection of residual standard deviations for various models. The plot is beneficial in that
- good models are distinguished from bad models;
- simple good models are distinguished from complicated good models.
- which models are poor (least desirable); and
- which models are good but complex (more desirable); and
- which models are good and simple (most desirable).
- Primary: A good-fitting prediction equation consisting of an
additive constant plus the most important main effects and
interactions.
- Secondary: The residual standard deviation for this good-fitting model.
- Vertical Axis: Ordered (largest to smallest) residual standard
deviations of a sequence of progressively more complicated
fitted models.
- Horizontal Axis: Factor/interaction identification of the last
term included into the linear model:
-
1 indicates factor X1;
2 indicates factor X2;
...
12 indicates the 2-factor X1*X2 interaction
123 indicates the 3-factor X1*X2*X3 interaction
etc. - Far right margin: Factor/interaction identification (built-in
redundancy):
-
1 indicates factor X1;
2 indicates factor X2;
...
12 indicates the 2-factor X1*X2 interaction
123 indicates the 3-factor X1*X2*X3 interaction
etc.If the design is a fractional factorial, the confounding structure is provided for main effects and 2-factor interactions.
The plot shows, from left to right, a model with only a constant and the model then augmented by including, one at a time, remaining factors and interactions. Each factor and interaction is incorporated into the model in an additive (rather than in a multiplicative or logarithmic or power, etc. fashion). At any stage, the ordering of the next term to be added to the model is such that it will result in the maximal decrease in the resulting residual standard deviation.
- What is a model?
- How do we select a goodness-of-fit metric for a model?
- How do we construct a good model?
- How do we know when to stop adding terms?
- What is the final form for the model?
- What are the advantages of the linear model?
- How do we use the model to generate predicted values?
- How do we use the model beyond the data domain?
- What is the best confirmation point for interpolation?
- How do we use the model for interpolation?
- How do we use the model for extrapolation?
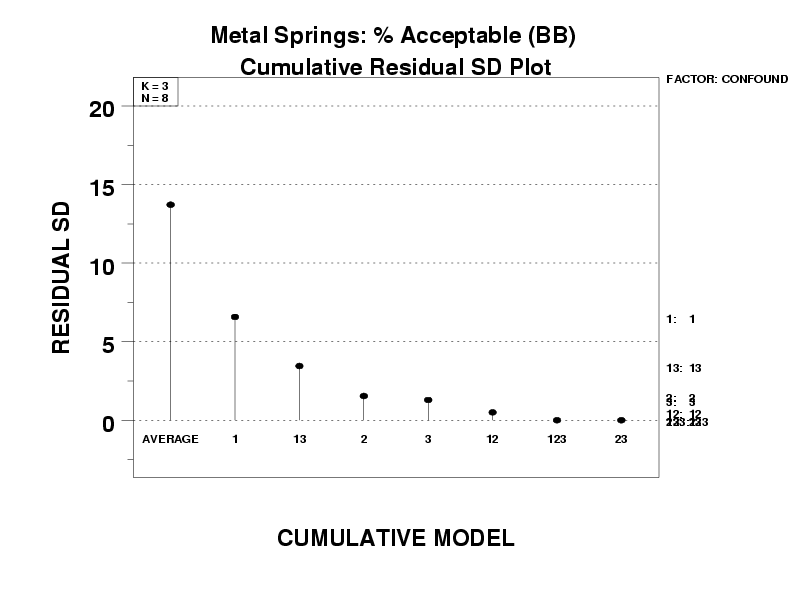
Including all terms would yield a perfect fit (residual standard deviation = 0) but would also result in an unwieldy model. Including only the first term (the average) would yield a simple model (only one term!) but typically will fit poorly. Although a formal quantitative stopping rule can be developed based on statistical theory, a less-rigorous (but good) alternative stopping rule that is graphical, easy to use, and highly effective in practice is as follows:
-
Keep adding terms to the model until the curve's
"elbow" is encountered. The "elbow point" is that
value in which there is a consistent, noticeably
shallower slope (decrease) in the curve. Include
all terms up to (and including) the elbow point
(after all, each of these included terms decreased
the residual standard deviation by a large
amount). Exclude any terms after the elbow point
since all such successive terms decreased the
residual standard deviation so slowly that the
terms were "not worth the complication of
keeping".
- The residual standard deviation (rsd) for
the "baseline" model
-
\( \hat{Y} = \bar{Y} = 71.25 \)
is sres = 13.7.
- As we add the next term, X1, the rsd drops nearly
7 units (from 13.7 to 6.6).
- If we add the term X1*X3, the
rsd drops another 3 units (from 6.6 to 3.4).
- If we add the term X2, the rsd drops another 2
units (from 3.4 to 1.5).
- When the term X3 is added, the reduction in the
rsd (from about 1.5 to 1.3) is negligible.
- Thereafter to the end, the total reduction in the rsd is from only 1.3 to 0.
In this case, the "kink" in the residual standard deviation curve is at the X2 term. Prior to that, all added terms (including X2) reduced the rsd by a large amount (7, then 3, then 2). After the addition of X2, the reduction in the rsd was small (all less than 1): 0.2, then 0.8, then 0.5, then 0.
The final recommended model in this case thus involves p = 4 terms:
- the average
- factor X1
- the X1*X3 interaction
- factor X2
-
\( \hat{Y} = \bar{Y} + B_{1}X_{1} + B_{13}X_{1}X_{3} + B_{2}X_{2} \)
-
\( \hat{Y} \) = 71.25
B1 = 11.5
B13 = 5
B2 = -2.5
The final fitted model is thus
-
\( \hat{Y} = 71.25 + 11.5 X_{1} + 5 X_{1}X_{3} - 2.5 X_{2} \)
| X1 | X2 | X3 | Y | \( \hat{Y} \) | Res |
|---|---|---|---|---|---|
| - | - | - | 67 | 67.25 | -0.25 |
| + | - | - | 79 | 80.25 | -1.25 |
| - | + | - | 61 | 62.25 | -1.25 |
| + | + | - | 75 | 75.25 | -0.25 |
| - | - | + | 59 | 57.25 | +1.75 |
| + | - | + | 90 | 90.25 | -0.25 |
| - | + | + | 52 | 52.25 | -0.25 |
| + | + | + | 87 | 85.25 | +1.75 |
-
\( s_{res} = \sqrt{ \frac{\sum_{i=1}^{n}{r_{i}^{2}}} {n-p} } \)
-
sres = 1.54 (or 1.5 if rounded to
1 decimal place)
- Good-fitting Parsimonious (constant + 3 terms) Model:
-
\( \hat{Y} = 71.25 + 11.5 X_{1} + 5 X_{1}X_{3} - 2.5 X_{2} \)
- Residual Standard Deviation for this Model
(as a measure of the goodness-of-fit for
the model):
-
sres = 1.54
