
|
|
KERNEL DENSITY PLOTName:
where K is the kernel function and h is the smoothing parameter or window width. Currently, Dataplot uses a Gaussian kernel function. This downweights points smoothly as the distance from x increases. The width parameter can be set by the user (see Note: below), although Dataplot will provide a default width that should produce reasonable results for most data sets. A kernel density plot can be considered a refinement of a histogram or frequency plot.
where <y> is the variable of raw data values; and where the <SUBSET/EXCEPT/FOR qualification> is optional. Note that <y> can be either a variable or a matrix. If <y> is a matrix, a kernel density plot will be generated for all values in the matrix.
<SUBSET/EXCEPT/FOR qualification> where <y1> ... <yk> is a list of response variables; and where the <SUBSET/EXCEPT/FOR qualification> is optional. This syntax will overlay multiple kernel density plots on the same plot. Note that the response variables (<y1> ... <yk> can be either variables or matrices (or a mix of variables and matrices). For matrices, a kernel density plot will be generated for all values in the matrix.
<SUBSET/EXCEPT/FOR qualification> where <y> is the variable of raw data values; <x1> is a group-id variable; and where the <SUBSET/EXCEPT/FOR qualification> is optional. This syntax will generate a kernel density plot for each distinct value in the group-id variable. The kernel density plots will be generated on the same page.
<SUBSET/EXCEPT/FOR qualification> where <y> is the variable of raw data values; <x1> is the first group-id variable; <x2> is the second group-id variable; and where the <SUBSET/EXCEPT/FOR qualification> is optional. This syntax will cross tabulate the group-id variables and generate a kernel density plot for each unique combination of values for the <x1> and <x2> group-id variables. The kernel density plots will be generated on the same page.
KERNEL DENSITY PLOT Y SUBSET TAG = 2 KERNEL DENSITY PLOT Y FOR I = 1 1 800 MULTIPLE KERNEL DENSITY PLOT Y1 Y2 Y3 REPLICATED KERNEL DENSITY PLOT Y X1 X2
This algorithm is based on the Fast Fourier Transform (FFT). The use of the FFT results in much greater computational efficiency. The article that accompanies this algorithm provides the details of how the FFT is used and provides timing estimates of this implemenation relative to an algorithm based on the definition of the kernel function.
You can set the number of points for the density curve using the following command:
where <value> defines the number of points.
where s is the sample standard deviation and IQ is the sample interquartile range. Silverman provides justification for this choice. Basically, it should perform reasonably for a wide variety of distributions. Note that the optimal width depends on the underlying function, which is what we are trying to estimate. If the underlying data is in fact normally distributed, then Silverman (1986) shows that the optimal width is
where n is the number of points in the raw data and s is the sample standard deviation of the raw data. It may be worthwhile to generate the density curve using several different values for the width. Silverman also recommends trying to transform skewed data sets to be symmetric. The width can be set with the following command:
To plot the estimated cdf, enter
To plot the estimated ppf, enter
To reset the plotting of the pdf, enter
Given that we can estimate the ppf function, we can use this to generate random numbers based on the kernel density plot. If you would like to generate random numbers, enter the command
where <value> is a number between 1 and the maximum number of rows. If <value> is set to 0 or a negative number, no random numbers are generated. Specifically, the following procedure is used:
where YMINIMUM and YMAXIMUM are the minimum and maximum values of the raw data and H is the window width.
DENSITY PLOT DENSITY TRACE The word MULTIPLE is optional for the MULTIPLE KERNEL DENSITY PLOT command.
B. W. Silverman (1986), "Density Estimation for Statistics and Data Analysis," Chapman & Hall. David Scott (1992), "Multivariate Density Estimation," John Wiley.
2010/02: Support for the MULTIPLE and REPLICATION syntax 2010/02: Support for matrix arguments and the TO syntax 2018/07: Support for SET KERNEL DENSITY PROBABILITY FUNCTION 2018/07: Support for SET KERNEL DENSITY RANDOM NUMBERS
MULTIPLOT SCALE FACTOR 2
MULTIPLOT 2 2
MULTIPLOT CORNER COORDINATES 0 0 100 100
.
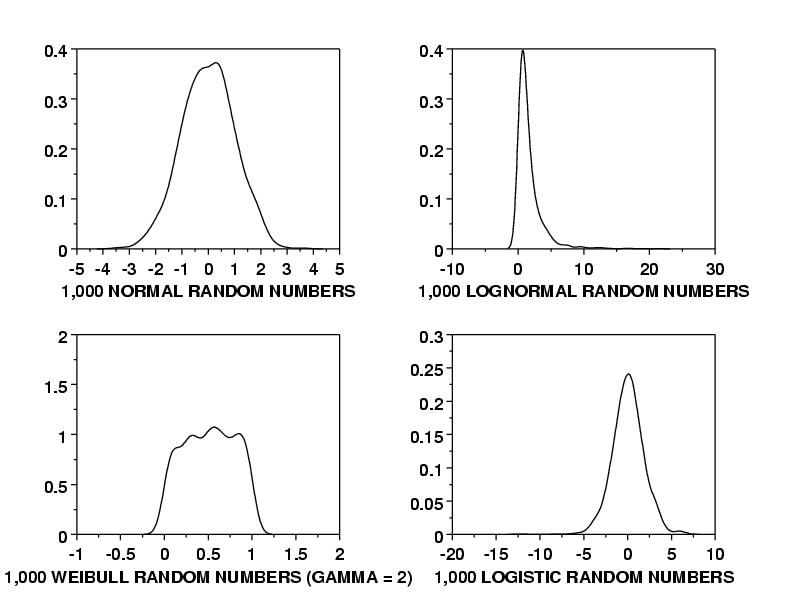
LET Y = NORMAL RANDOM NUMBERS FOR I = 1 1 1000
X3LABEL 1,000 NORMAL RANDOM NUMBERS
KERNEL DENSITY PLOT Y
.
LET Y = LOGNORMAL RANDOM NUMBERS FOR I = 1 1 1000
X3LABEL 1,000 LOGNORMAL RANDOM NUMBERS
KERNEL DENSITY PLOT Y
.
LET GAMMA = 2
LET Y = WEIBULL RANDOM NUMBERS FOR I = 1 1 1000
X3LABEL 1,000 WEIBULL RANDOM NUMBERS (GAMMA = 2)
KERNEL DENSITY PLOT Y
.
LET Y = LOGISTIC RANDOM NUMBERS FOR I = 1 1 1000
X3LABEL 1,000 LOGISTIC RANDOM NUMBERS
KERNEL DENSITY PLOT Y
END OF MULTIPLOT
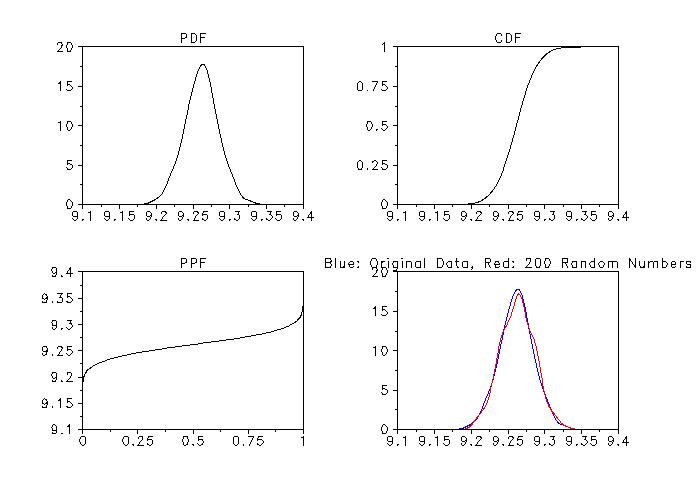
Program 2:
. Step 1: Read the data
.
skip 25
read zarr13.dat y
skip 0
.
. Step 2: Plot control features
.
multiplot corner coordinates 5 5 95 95
multiplot scale factor 2
title offset 2
title case asis
label case asis
case asis
.
. Step 3: Generate the kernel density plot
.
multiplot 2 2
.
title PDF
kernel density plot y
.
title CDF
set kernel density probability function cdf
kernel density plot y
.
title PPF
set kernel density probability function ppf
set kernel density random numbers 200
kernel density plot y
.
read dpst1f.dat yrand
line color blue red
title Blue: Original Data, Red: 200 Random Numbers
set kernel density probability function pdf
multiple kernel density plot y yrand
.
end of multiplot
Date created: 08/14/2001 |
Last updated: 12/04/2023 Please email comments on this WWW page to [email protected]. | ||||||||||||