|
|
DISTRIBUTIONAL BOOTSTRAPName:
One limitation of this method is that it does not provide a method for finding uncertainty intervals for these estimates. To address this, we have extended the BOOTSTRAP PLOT command to support a number of probability distributions. The bootstrap is a non-parametric method for calculating a sampling distribution for a statistic. The bootstrap calculates the statistic with N different subsamples. The subsampling is performed with replacement. To apply the bootstrap to the univariate distributional modeling problem, we do the following:
For the bootstrap plot, there will be a separate curve drawn for each parameter estimated. In addition, there will be a curve drawn for the PPCC value (or the Kolmogorov-Smirnov statistic). The vertical axis contains the computed value of these estimated parameters and the horizontal axis contains the sample number (for k = 1, 2, ..., N). The bootstrap plot is typically followed by some type of distributional plot, such as a histogram, for each estimated parameter. This is demostrated in the Program sample below. Dataplot also supports bootstrap computations for the case when there is one group variable. In this case, the horizontal axis is group id and the vertical axis contains the computed values of the estimated parameters for that group (the parameters are offset horizontally). The number of bootstrap samples is applied to each group. For example,if the requested number of bootstrap samples is 100, then each group will have 100 bootstrap samples applied.
where <y> is the response variable; <dist> is one of the following distributions:
ARCSINE CAUCHY COSINE EXPONENTIAL GUMBEL (EXTREME VALUE TYPE 1) HALF CAUCHY HALF LOGISTIC HALF NORMAL HYPERBOLIC SECANT LAPLACE (DOUBLE EXPONENTIAL) LOGISTIC NORMAL RAYLEIGH SEMI-CIRCULAR SLASH UNIFORM This syntax estimates the location and scale parameters for each bootstrap sample using a probability plot.
<SUBSET/EXCEPT/FOR qualification> where <y> is the response variable; <x> is the censoring variable; <dist> is one of the distributions given for Synatx 1; and where the <SUBSET/EXCEPT/FOR qualification> is optional. This syntax estimates the location and scale parameters for each bootstrap sample using a censored probability plot. The censoring variable should contain a value of 1 to indicate a failure time and a value of 0 to indicate a censoring time.
where <y> is the response variable; <dist> is one of the following distributions:
BRADFORD CHI CHI-SQUARE DOUBLE GAMMA DOUBLE WEIBULL ERROR (SUBBOTIN) FATIGUE LIFE FOLDED T FRECHET GAMMA GENERALIZED EXTREME VALUE GENERALIZED HALF LOGISTIC GENERALIZED LOGISTIC GENERALIZED PARETO GEOMETRIC EXTREME EXPONENTIAL INVERTED GAMMA INVERTED WEIBULL LOG DOUBLE EXPONENTIAL (LOG LAPLACE) LOG GAMMA LOG LOGISTIC LOGNORMAL PARETO PARETO SECOND KIND POWER POWER NORMAL RECIPROCAL SKEW LAPLACE (SKEW DOUBLE EXPONENTIAL) T TUKEY-LAMBDA VON MISES WALD WRAPPED CAUCHY WEIBULL This syntax estimates the shape parameter using a PPCC plot and then estimates the location and scale parameters using a probability plot for each bootstrap sample .
<SUBSET/EXCEPT/FOR qualification> where <y> is the response variable; <x> is the censoring variable; <dist> is one of the distributions given for syntax 3; and where the <SUBSET/EXCEPT/FOR qualification> is optional. This syntax estimates the shape parameter using a censored PPCC plot and then estimates the location and scale parameters using a censored probability plot for each bootstrap sample. The censoring variable should contain a value of 1 to indicate a failure time and a value of 0 to indicate a censoring time.
where <y> is the response variable; <dist> is one of the distributions given for syntax 3; and where the <SUBSET/EXCEPT/FOR qualification> is optional. This syntax estimates the shape parameter using a KS plot and then estimates the location and scale parameters using a probability plot for each bootstrap sample.
where <y> is the response variable; <dist> is one of the following distributions:
F FOLDED NORMAL G-AND-H INVERSE GAUSSIAN GENERALIZED GAMMA This syntax estimates the two shape parameters using a PPCC plot and then estimates the location and scale parameters using a probability plot for each bootstrap sample.
<SUBSET/EXCEPT/FOR qualification> where <y> is the response variable; <x> is the censoring variable; <dist> is one of the distributions given in syntax 6; and where the <SUBSET/EXCEPT/FOR qualification> is optional. This syntax estimates the two shape parameters using a censored PPCC plot and then estimates the location and scale parameters using a censored probability plot for each bootstrap sample. The censoring variable should contain a value of 1 to indicate a failure time and a value of 0 to indicate a censoring time.
where <y> is the response variable; <dist> is one of the following distributions:
EXPONENTIAL FOLDED NORMAL GUMBEL (EXTREME VALUE TYPE 1) LAPLACE (DOUBLE EXPONENTIAL) LOGISTIC NORMAL RAYLEIGH UNIFORM This syntax estimates the location and scale parameters using maximum likelihood for each bootstrap sample.
<SUBSET/EXCEPT/FOR qualification> where <y> is the response variable; <x> is the censoring variable; <dist> is one of the following distributions:
EXPONENTIAL This syntax estimates the location and scale parameters using maximum likelihood for each bootstrap sample. The censoring variable should contain a value of 1 to indicate a failure time and a value of 0 to indicate a censoring time.
where <y> is the response variable; <dist> is one of the following distributions:
FATIGUE LIFE GAMMA GENERALIZED PARETO GEOMETRIC EXTREME EXPONENTIAL INVERSE GAUSSIAN LOGNORMAL PARETO WEIBULL This syntax estimates the shape and scale parameters (the Beta, Pareto, and inverse Gaussian estimate the two shape parameters but no scale parameter) using maximum likelihood for each bootstrap sample.
<SUBSET/EXCEPT/FOR qualification> where <y> is the response variable; <x> is the censoring variable; <dist> is one of the following distributions:
CENSORED LOGNORMAL CENSORED WEIBULL This syntax estimates the location and scale parameters using maximum likelihood for each bootstrap sample. The censoring variable should contain a value of 1 to indicate a failure time and a value of 0 to indicate a censoring time.
where <y> is the response variable; <dist> is one of the following distributions:
This syntax estimates the shape, location, and scale parameters using maximum likelihood for each bootstrap sample.
BOOTSTRAP NORMAL MLE PLOT Y BOOTSTRAP WEIBULL PLOT Y BOOTSTRAP WEIBULL KS PLOT Y BOOTSTRAP WEIBULL CENSORED PLOT Y X
dpst1f.dat The estimates for each bootstrap sample are written to file dpst1f.dat. You can read the variables written to dpst1f.dat to generate histograms and to compute selected percentiles. The order is:
location parameter scale parameter first shape parameter second shape parameter ppcc (or ks) value If a particular syntax does not generate one or more of these values, then they are omitted (e.g., the normal distribution does not generate estimates for any shape parameters). The following example generates a Weibull bootstrap plot and then reads the bootstrap estimates from dpst1f.dat.
SKIP 0 READ DPST1F.DAT ALOC ASCALE AGAMMA APPCC MULTIPLOT 2 2 RELATIVE HISTOGRAM ALOC RELATIVE HISTOGRAM ASCALE RELATIVE HISTOGRAM AGAMMA RELATIVE HISTOGRAM APPCC END OF MULTIPLOT dpst2f.dat Selected percentiles are written to dpst2f.dat. The order is:
Parameter number - parameters are ordered as they are in dpst1f.dat Mean Standard Deviation Median 2.5 percentile 97.5 percentile 5.0 percentile 95.0 percentile 0.5 percentile 99.5 percentile
If you enter the command
you will get bootstrap estimates for the following percentiles:
If you would like to specify the specific percentiles to estimate, enter the command
with YPERC denoting a variable that contains the desired percentiles. This is demonstrated in the sample program below. By default, two sided confidence intervals are generated for the percentiles. The following commands can be used to generate either lower one sided or upper one sided intervals
SET BOOTSTRAP DISTRIBUTIONAL PERCENTILES UPPER To turn off the computation of the percentile confidence intervals, enter
To reset the default of two sided intervals, enter
LET GAMMA2 = 10 BOOTSTRAP WEIBULL PLOT Y One recommendation is to generate the bootstrap plot for a relatively small number of samples (e.g., 50) and use that to determine a reasonable range for the shape parameter. Enter HELP PPCC PLOT to see the relevant parameter for the desired distribution.
The BCA option is not currently supported for the bootstrap distributional plots.
The full sample is used to generate the parameter estimates of the distribution. Then the bootstrap samples are generated by generating random numbers from the specified distribution using the parameters estimated from the full sample. The following command will specify this alternate method of bootstrapping be used:
To restore the default method of bootstrapping the data values, enter the command
The parameteric option is still being tested and may not work correctly for some of the distributions.
MAXIMUM LIKELIHOOD is a synonym for MLE
Efron and Tibshirabi (1993), "An Introduction to the Bootstrap", Springer-Verlang.
. Following Sample Macro demonstrates the use of the
. bootstrap with a Weibull distribution.
.
. Step 0: Create some sample Weibull data
.
dimension 50 columns
.
let gamma = 2.3
let y = weibull random numbers for i = 1 1 100
.
. Step 1: Perform PPCC/Probability Plot Analysis,
. Perform K-S goodness of fit test
.
set ipl1na distboo1.ps
device 2 postscript
device 2 color on
.
multiplot 2 2
multiplot corner coordinates 0 0 100 100
multiplot scale factor 1.5
y1label displacement 12
.
title displacement 2
x1label displacement 12
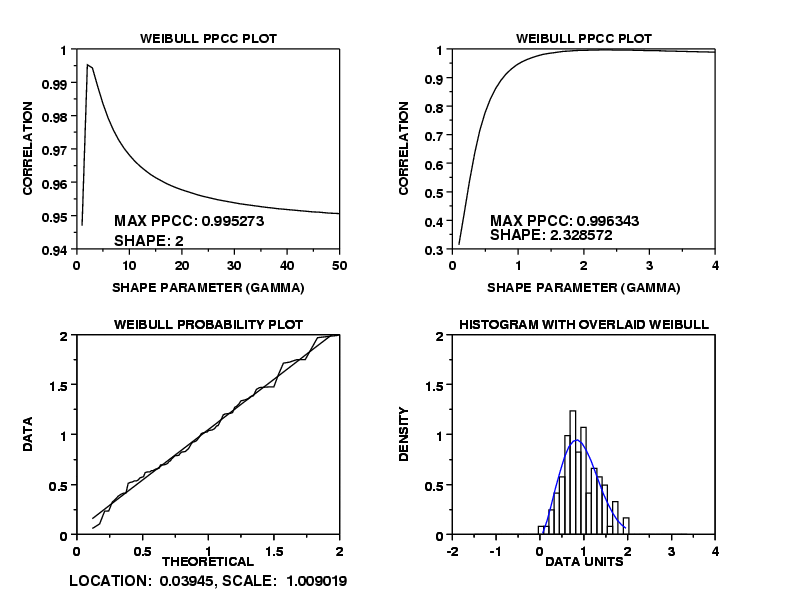
title Weibull PPCC Plot
x1label Shape Parameter (gamma)
y1label Correlation
weibull ppcc plot y
justification left
height 3.5
move 25 28
text Max PPCC: ^maxppcc
move 25 21
text Shape: ^shape
let gamma1 = shape - 2
if gamma1 <= 0
let gamma1 = 0.1
end of if
let gamma2 = shape + 2
title Weibull PPCC Plot
weibull ppcc plot y
move 25 28
text Max PPCC: ^maxppcc
move 25 23
text Shape: ^shape
let gamma = shape
if n <= 200
character x
line blank
else
line solid
character blank
end of if
.
title Weibull Probability Plot
x1label displacement
x1label Theoretical
y1label Data
weibull probability plot y
justification center
move 50 2
text Location: ^ppa0, Scale: ^ppa1
let iplot = 3
multiplot 2 2 iplot
line solid
character blank
limits freeze
pre-erase off
let function f = ppa0 + ppa1*x
let zmin = minimum xplot
let zmax = maximum xplot
let ainc2 = (zmax - zmin)/10
plot f for x = zmin ainc2 zmax
limits
pre-erase on
let iplot = iplot + 1
multiplot 2 2 iplot
title Histogram with Overlaid Weibull
x1label Data Units
y1label Density
relative histogram y
multiplot 2 2 iplot
limits freeze
pre-erase off
let loc2=ppa0
let scale2=ppa1
line solid
char blank
line color blue
let amin = minimum y
let amax = maximum y
let ainc = 0.1
plot weipdf(x,shape,loc2,scale2) for x = amin ainc amax
limits
pre-erase on
line color black
delete gamma gamma1 gamma2
end of multiplot
device 2 close
.
. Step 2: Now perform a bootstrap analysis
.
feedback off
capture distboot.out
write " "
write "BOOTSTRAP-BASED INTERVALS"
write " "
set maximum likelihood percentiles default
bootstrap samples 200
let gamma1 = 0.2
let gamma2 = 5
set ipl1na distboo2.ps
device 2 postscript
device 2 color on
multiplot 2 3
multiplot corner coordinates 0 0 100 100
multiplot scale factor 1.7
y1label Parameter Estimate
x1label
x2label Bootstrap Sample
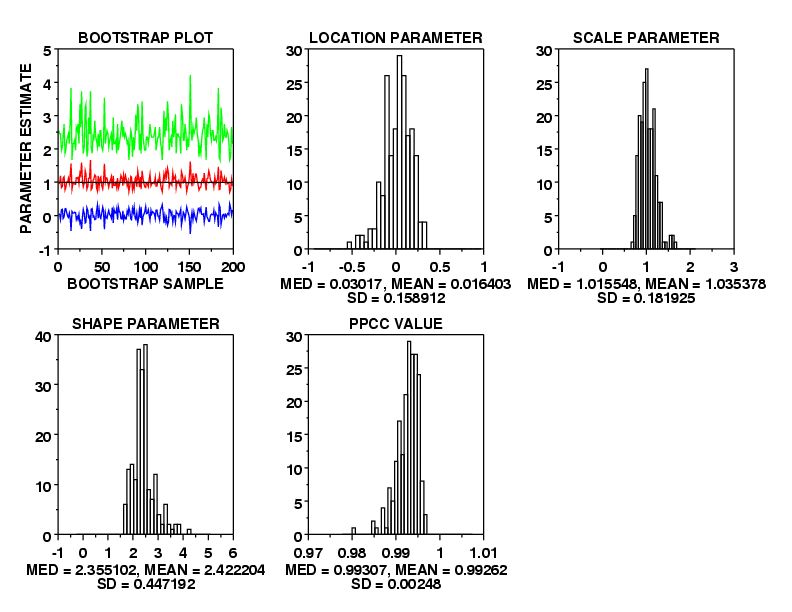
title Bootstrap Plot
line color blue red green
limits
bootstrap weibull plot y
line color black all
.
delete aloc ascale ashape appcc
skip 0
read dpst1f.dat aloc ascale ashape appcc
y1label
x2label
x3label displacement 16
title Location Parameter
let amed = median aloc
let amean = mean aloc
let asd = sd aloc
x2label Med = ^amed, Mean = ^amean
x3label SD = ^asd
histogram aloc
title Scale Parameter
let amed = median ascale
let amean = mean ascale
let asd = sd ascale
x2label Med = ^amed, Mean = ^amean
x3label SD = ^asd
histogram ascale
title Shape Parameter
let amed = median ashape
let amean = mean ashape
let asd = sd ashape
x2label Med = ^amed, Mean = ^amean
x3label SD = ^asd
histogram ashape
title PPCC Value
let amed = median appcc
let amean = mean appcc
let asd = sd appcc
x2label Med = ^amed, Mean = ^amean
x3label SD = ^asd
histogram appcc
x3label displacement
.
device 2 close
.
let alpha = 0.05
let xqlow = alpha/2
let xqupp = 1 - alpha/2
.
write "Bootstrap-based Confidence Intervals"
write "alpha = ^alpha"
write " "
.
let xq = xqlow
let loc95low = xq quantile aloc
let xq = xqupp
let loc95upp = xq quantile aloc
let xq = xqlow
let sca95low = xq quantile ascale
let xq = xqupp
let sca95upp = xq quantile ascale
let xq = xqlow
let sha95low = xq quantile ashape
let xq = xqupp
let sha95upp = xq quantile ashape
write "Confidence Interval for Location: (^loc95low,^loc95upp)"
write "Confidence Interval for Scale: (^sca95low,^sca95upp)"
write "Confidence Interval for Gamma: (^sha95low,^sha95upp)"
.
. Now generate confidence intervals for percentiles
.
serial read p
0.5 1 2.5 5 10 20 30 40 50 60 70 80 90 95 97.5 99 99.5
end of data
let nperc = size p
skip 1
read matrix dpst4f.dat xqp
write " "
loop for k = 1 1 nperc
let xqptemp = p(k)
let amed = median xqp^k
let xqpmed(k) = amed
let xq = xqlow
let atemp = xq quantile xqp^k
let xq95low(k) = atemp
let xq = xqupp
let atemp = xq quantile xqp^k
let xq95upp(k) = atemp
end of loop
set table title "Bootstrap Based Confidence Intervals for Percentiles"
set table spacing 15
set write decimals 7
write " "
write "Confidence Intervals for Percentiles"
write p xqpmed xq95low xq95upp
end of capture
delete xqp xqpmed xq95low xq95upp
delete gamma1 gamma2
BOOTSTRAP-BASED INTERVALS
Bootstrap-based Confidence Intervals
alpha = 0.05
Confidence Interval for Location: (-0.4112,0.272742)
Confidence Interval for Scale: (0.744203,1.572763)
Confidence Interval for Gamma: (1.738776,3.748062)
Confidence Intervals for Percentiles
VARIABLES--P XQPMED XQ95LOW XQ95UPP
0.5000000 0.1427522 -0.0264724 0.3189068
1.0000000 0.1783569 0.0333498 0.3433715
2.5000000 0.2441821 0.1315464 0.3925191
5.0000000 0.3210546 0.2229533 0.4490436
10.0000000 0.4301926 0.3367559 0.5266151
20.0000000 0.5761956 0.4959525 0.6575613
30.0000000 0.6924722 0.6142470 0.7801363
40.0000000 0.8017390 0.7214258 0.8862920
50.0000000 0.9073263 0.8198442 0.9952904
60.0000000 1.0129241 0.9191304 1.1054595
70.0000000 1.1306920 1.0393872 1.2280047
80.0000000 1.2808006 1.1713773 1.3832619
90.0000000 1.4895294 1.3569634 1.5912455
95.0000000 1.6622919 1.5139780 1.7756084
97.5000000 1.8108935 1.6356139 1.9443940
99.0000000 1.9902619 1.7803770 2.1564791
99.5000000 2.1085887 1.8710965 2.3045762
Date created: 04/20/2005 |
Last updated: 12/04/2023 Please email comments on this WWW page to [email protected]. | ||||||||||||||||||||||