|
|
CROSS TABULATE PLOTName:
This plot is an extension of the STATISTIC PLOT. The STATISTIC PLOT uses one index variable while the CROSS TABULATE PLOT uses two index variables. The X axis coordinate is determined from the two group variables in the following way:
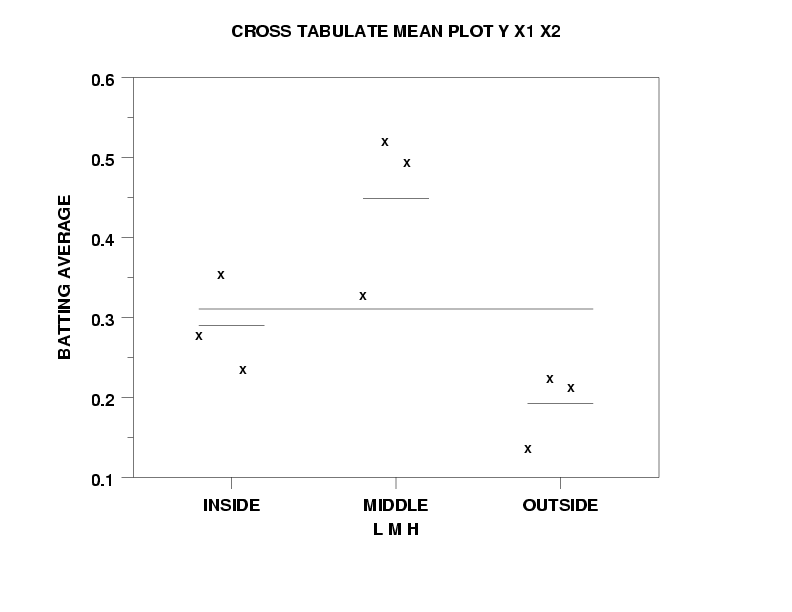
The syntax CROSS TABULATE X1 X2 is a special case. It plots the value of X1 on the X axis and the value of X2 on the Y axis. The plot character is then set to the count for that cell (this is done automatically and you do not need to set the plot character). This form of the plot has application in the design of experiments. The cross tabulate plot is used to answer the question--"Does the subsample statistic change over different subsamples?". The plot consists of:
The cross tabulate plot yields 2 traces:
where <stat> is one of the following statistics:
SUM, PRODUCT, SIZE (or NUMBER or SIZE), STANDARD DEVIATION, STANDARD DEVIATION OF MEAN, AVERAGE ABSOLUTE DEVIATION (or AAD), MEDIAN ABSOLUTE DEVIATION (or MAD), VARIANCE, VARIANCE OF THE MEAN, RELATIVE STANDARD DEVIATION, RELATIVE VARIANCE (or COEFFICIENT OF VARIATION), RANGE, MIDRANGE, MAXIMUM, MINIMUM, EXTREME, LOWER HINGE, UPPER HINGE, LOWER QUARTILE, UPPER QUARTILE, <FIRST/SECOND/THIRD/FOURTH/FIFTH/SIXTH/SEVENTH/EIGHTH/ NINTH/TENTH> DECILE, SKEWNESS, KURTOSIS, NORMAL PPCC, AUTOCORRELATION, AUTOCOVARIANCE, SINE FREQUENCY, SINE AMPLITUDE, CP, CPK, EXPECTED LOSS, PERCENT DEFECTIVE, TAGUCHI SN0 (or SN), TAGUCHI SN+ (or SNL), TAGUCHI SN- (or SNS), TAGUCHI SN00 (or SN2); <x1> is the first subsample identifier variable (this variable appears on the horizontal axis); <x2> is the second subsample identifier variable (this variable appears on the horizontal axis); and where the <SUBSET/EXCEPT/FOR qualification> is optional. This syntax is used for statistics that require one response variable to compute.
<SUBSET/EXCEPT/FOR qualification> where <stat> is one of the following statistics:
LINEAR RESSD, LINEAR CORRELATION, CORRELATION, RANK CORRELATION, COVARIANCE, RANK COVARIANCE, WINSORIZED COVARIANCE, WINSORIZED COVARIANCE, BIWEIGHT MIDCOVARIANCE, BIWEIGHT MIDCORRELATION, PERCENTAGE BEND CORRELATION; <y2> is the second response variable; <x1> is the first subsample identifier variable (this variable appears on the horizontal axis); <x2> is the second subsample identifier variable (this variable appears on the horizontal axis); and where the <SUBSET/EXCEPT/FOR qualification> is optional. This syntax is used for statistics that require two response variables to compute. If a linear fit is performed, the first variable is the dependent variable while the second variable is the independent variable.
<SUBSET/EXCEPT/FOR qualification> where <stat> is one of the following statistics:
<wt> is the weights response variable; <x1> is the first subsample identifier variable (this variable appears on the horizontal axis); <x2> is the second subsample identifier variable (this variable appears on the horizontal axis); and where the <SUBSET/EXCEPT/FOR qualification> is optional. This syntax is used to compute the weighted version of the specified statistic for a single response variable.
<SUBSET/EXCEPT/FOR qualification> where <stat> is one of the following statistics:
<y2> is the second response variable; <x1> is the first subsample identifier variable (this variable appears on the horizontal axis); <x2> is the second subsample identifier variable (this variable appears on the horizontal axis); and where the <SUBSET/EXCEPT/FOR qualification> is optional. This syntax is used to compute the difference between two response variables for the specified statistic. The variables can be either independent (i.e., not paired) or dependent (i.e., paired), but the response variables must have the same number of elements.
CROSS TABULATE STANDARD DEVIATION PLOT Y X1 X2
HELP SCATTER PLOT MATRIX
SET CROSS TABULATE PLOT DIMENSION 2
SET CROSS TABULATE PLOT DIMENSION 1
READ RIPKEN.DAT Y X1 TO X4 . CHARACTER X BLANK BLANK LINE BLANK SOLID SOLID TITLE AUTOMATIC Y1LABEL BATTING AVERAGE XLIMITS 1 3 XTIC OFFSET 0.6 0.6 TIC OFFSET UNITS DATA MAJOR XTIC MARK NUMBER 3 MINOR XTIC MARK NUMBER 0 XTIC MARK LABEL FORMAT ALPHA XTIC MARK LABEL CONTENT INSIDE MIDDLECR()LSP()MSO()H OUTSIDE CROSS TABULATE MEAN PLOT Y X1 X2
Date created: 06/05/2001 |
Last updated: 12/04/2023 Please email comments on this WWW page to [email protected]. | |||||||||||||||||||||||||||||||||||||